小怪物米米卡
标签:arduino DIY intel Edison
短笛大魔王 发布于 2016-09-26 14:17

嗷~~ 我是小怪物米米卡!你说什么?嗷~~我是小怪物米米卡!
这个小怪物刚刚来到地球,你需要教它怎么说话!如果你对着它的音频天线说话,它就会重复你的话。按一下按键,它还会改变音调。
在动手之前,intel edison需要:1. 已经升级了硬件
2. 能连到无线网络
3. 可以用迷你USB或wifi连接ssh/scp
Step 1: 准备需要的工具和材料

1. intel Edison和arduino 扩展板
2. 1个intel Edison 电源
3. 1个麦克风 1个USB声卡(带音频输入输出)
4. 带迷你杰克头的电源控制的扬声器
5. 螺母和螺栓
6. 喷胶或胶布
Step 2: 准备米米卡的外壳
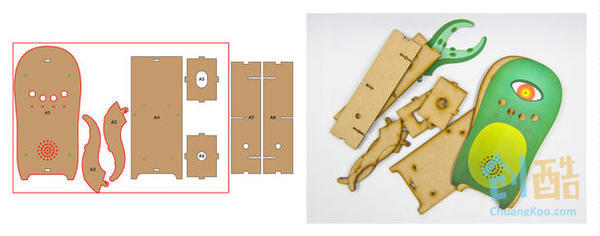
根据附件的图纸,准备好外壳的各个部分,打印出装饰的图片,方便最后组装
附件:
Step 3: 焊电路
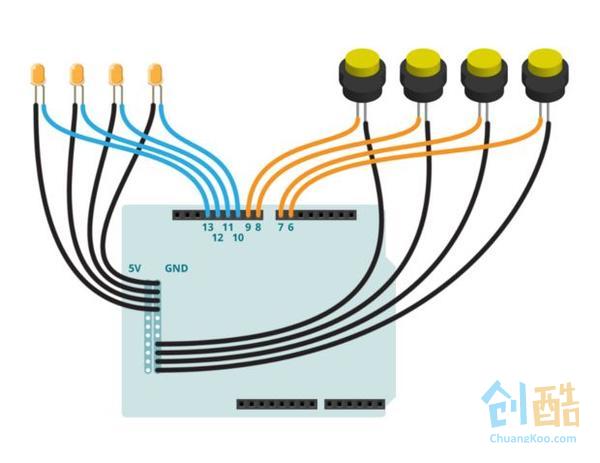
Step 4: 组装



1. 把A7和A8装到A1上
2. 用胶布或双面胶把彩色外观贴到A1,A2,A3上
3. 把按钮放到A1上设计好的孔里, 注意按钮的顺序要与LEDs匹配,把LED放进A1上设计好的孔里,注意LED的顺序要与按钮匹配
4. 在A4上安装Arduino扩展板
5. 连接声音元件、声卡、麦克风和扬声器、把电路装到Arduino 扩展板上
6. 把A5和A6连到A1上
7. 从上面的孔装入麦克风,从下面的孔装电线
8. 在A7和A8上插入A2和A3,用橡皮筋固定它们
9. 用A4完成组装,小心电线。在盖上最后的盖子前,最好先测试下电路是否能用
Step 5: 配置声卡+编程

如果你有最新的intel Edison系统映像,那很可能你不需要装任何驱动,声卡就能用。插好USB声卡,打开开关。在打开开关前,请确保连好电源。否则,Intel Edison 无法加电
先用通用的 alsamixer检查下声卡能否正常工作和控制音量
在控制台输入“alsamixer”打开界面。按下F6,选择声卡。在这里,我是选的C-Media USB头戴式耳机设置。把输出音量调低,这样不会太吵。通过调节这个,找到合适的音量。
安装python库
升级设置工具,它是用来安装程序包的Python工具。确保你能连上网络,在命令控制台输入如下语句:
wget https://bitbucket.org/pypa/setuptools/raw/bootstrap/ez_setup.py -O - | python
下载pyaudio,这是我们要用来处理声音输入/输出的Python库。在命令控制台输入如下语句:
wget people.csail.mit.edu/hubert/pyaudio/packages/pyaudio-0.2.8.tar.gz -o ./pyaudio.tar.gz
在命令控制台输入如下语句解码:
tar -x pyaudio.tar.gz
安装pyaudio 根据导航进入pyaudio的文件夹,在命令控制台输入如下语句:
python setup.py install
安装portaudio,这是让音频设备正常工作的Linux工具。在命令控制台输入如下语句:
opkg install libportaudio2
安装numpy,这是处理数据的Python库,它会在音频处理的实际进程上用到。在命令控制台输入如下语句:
opkg install python-numpy
intel Edison的移动脚本
从附件下载python脚本,用sip把它全部复制到intel Edison
在命令控制台输入如下语句:
scp Mimic.py root@your-edison-ip:~/
在命令控制台开始编写小怪物米米卡的程序:
python ~/Mimic.py
源代码如下:"""
Mimic:
Let Edison mimic your voice in a funny way
"""
import pyaudio
import audioop
import numpy as np
import struct
import wave
import time
import mraa
led_pins=[13,12,11,10]
btn_pins=[9,8,7,6]
levels=[-7,-3,3,7]
leds=[]
btns=[]
CHUNK = 1024
WIDTH = 2
CHANNELS = 1
RATE = 44100
RECORD_SECONDS = 5
level=-1
swidth=2
#Volume needed to activate the programme
activate_volume=2000
def dimAllLeds():
for i in range(4):
leds[i].write(0)
def speedx(snd_array, factor):
""" Speeds up / slows down a sound, by some factor. """
indices = np.round( np.arange(0, len(snd_array), factor) )
indices = indices[indices < len(snd_array)].astype(int)
return snd_array[ indices ]
def stretch(snd_array, factor, window_size, h):
""" Stretches/shortens a sound, by some factor. """
phase = np.zeros(window_size)
hanning_window = np.hanning(window_size)
result = np.zeros( len(snd_array) /factor + window_size)
for i in np.arange(0, len(snd_array)-(window_size+h), h*factor):
# two potentially overlapping subarrays
a1 = snd_array[i: i + window_size]
a2 = snd_array[i + h: i + window_size + h]
# the spectra of these arrays
s1 = np.fft.fft(hanning_window * a1)
s2 = np.fft.fft(hanning_window * a2)
# rephase all frequencies
phase = (phase + np.angle(s2/s1)) % 2*np.pi
a2_rephased = np.fft.ifft(np.abs(s2)*np.exp(1j*phase))
i2 = int(i/factor)
result[i2 : i2 + window_size] += hanning_window*a2_rephased
result = ((2**(16-4)) * result/result.max()) # normalize (16bit)
return result.astype('int16')
def pitchshift(snd_array, n, window_size=2**13, h=2**11):
""" Changes the pitch of a sound by ``n`` semitones. """
factor = 2**(1.0 * n / 12.0)
stretched = stretch(snd_array, 1.0/factor, window_size, h)
return speedx(stretched[window_size:], factor)
if __name__=="__main__":
#Initialize the buttons and leds
for i in range(0,4):
led=mraa.Gpio(led_pins[i])
led.dir(mraa.DIR_OUT)
btn=mraa.Gpio(btn_pins[i])
btn.dir(mraa.DIR_IN)
btn.mode(mraa.MODE_PULLUP)
leds.append(led)
btns.append(btn)
#Initialize audio stream
p = pyaudio.PyAudio()
stream = p.open(format=p.get_format_from_width(WIDTH),
channels=CHANNELS,
rate=RATE,
input=True,
output=True,
frames_per_buffer=CHUNK)
#The main loop
while True:
frames=""
stream.start_stream()
#Work to do before mimic starts
while True:
#Check if buttons are pressed
for i in range(4):
if btns[i].read()==0:
dimAllLeds()
leds[i].write(1)
level=levels[i]
#Check if someone is speaking
data = stream.read(CHUNK)
rms=audioop.rms(data,2)
if rms>activate_volume:
frames=frames+data
break
#Start recording
timer=0
print("* recording")
while True:
try:
data = stream.read(CHUNK)
frames=frames+data
rms=audioop.rms(data,2)
if rms<activate_volume:
if time.time()-timer>1:
break
else:
timer=time.time()
except:
pass
#Do the pitch shifting magic
frames = struct.unpack("%dh"%(len(frames)/swidth), frames)
frames = np.array(frames)
frames=pitchshift(frames, level)
frames=struct.pack("%dh"%(len(frames)),*list(frames))
#Play the modified sound
data = frames[0:CHUNK]
i=0
while data != '':
stream.write(data)
i=i+1
data = frames[i*CHUNK:(i+1)*CHUNK]
print("* done")
stream.stop_stream()
stream.close()
p.terminate()
对准麦克风清楚大声的说话,小怪物米米卡就会用搞笑的声音重复你的话了~~~~
